Video Overview
Abstract
Modern imitation learning methods, including visuomotor and Vision-Language-Action (VLA) policies, typically output high-level action references that are executed by low-level controllers. However, the absence of higher-order reference signals, together with the policy's lack of awareness of the underlying low-level control dynamics during training, inevitably induces an execution gap. As a result, realized actions deviate systematically from policy-commanded ones, with a critical impact on precision-sensitive manipulation. Prior work either modifies the policy architecture or the low-level controller, both requiring intrusive changes to the pretrained policy or packaged controller. This raises a natural question: when the policy and controller are both treated as inaccessible black boxes, can we bridge the execution gap? We propose Adaptive Policy EXecution (APEX), a plug-and-play framework inserted between the policy and the controller that reconstructs a dynamically feasible reference from policy outputs and adapts at test-time according to low-level state feedback, with a provable convergence guarantee. Extensive empirical studies show that APEX reduces controller-induced tracking error by 41.2% on demonstration replay and improves manipulation success by 4.8--25.8 percentage points across four visuomotor and VLA policy classes.
Test-Time Execution Gap
Learned policies output high-level action references, but the robot executes them through a low-level controller. At test time, missing higher-order references and unknown controller dynamics can make the realized motion deviate from the commanded motion, which is especially harmful for precision-sensitive manipulation.
Method
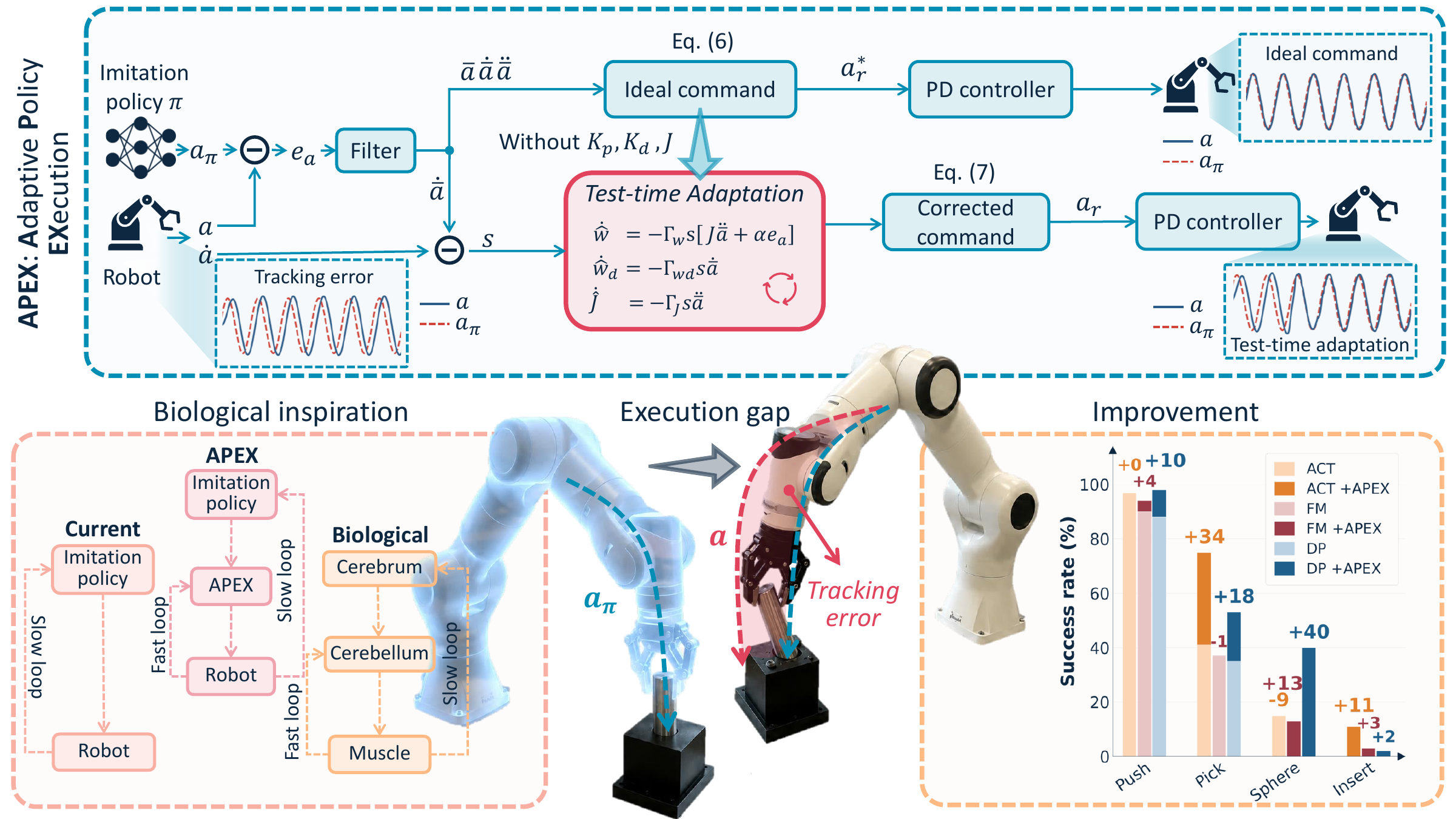
APEX has two components. First, an adaptive passive filter turns policy outputs into a smooth, dynamically feasible reference with velocity- and acceleration-like signals.
Second, feedback-driven adaptive terms refine this reference during execution to compensate for unknown dynamics and controller parameters.
Black-Box Interface
No policy retraining or controller modification.
Reference Reconstruction
Recover smooth reference signals from policy outputs.
Online Adaptation
Update correction terms from real-time feedback.
Experiments
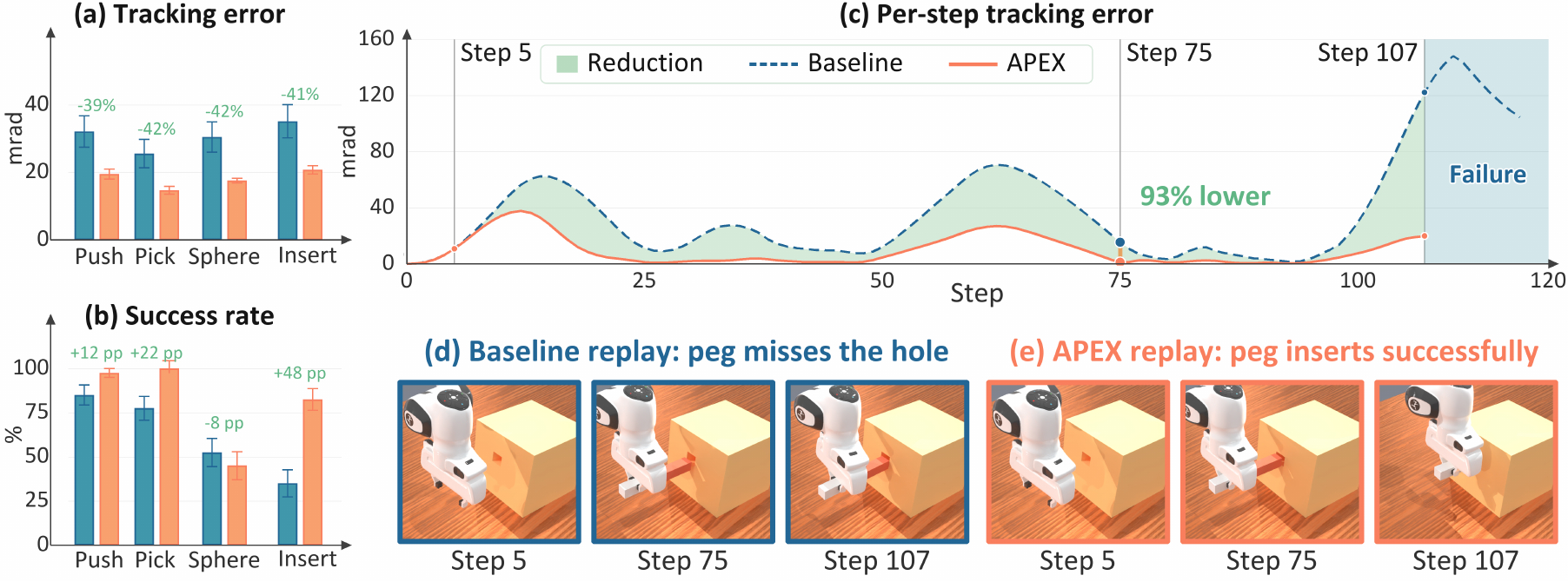
We evaluate APEX by isolating controller-induced replay error, deploying frozen learned policies, and testing across policy classes and platforms.
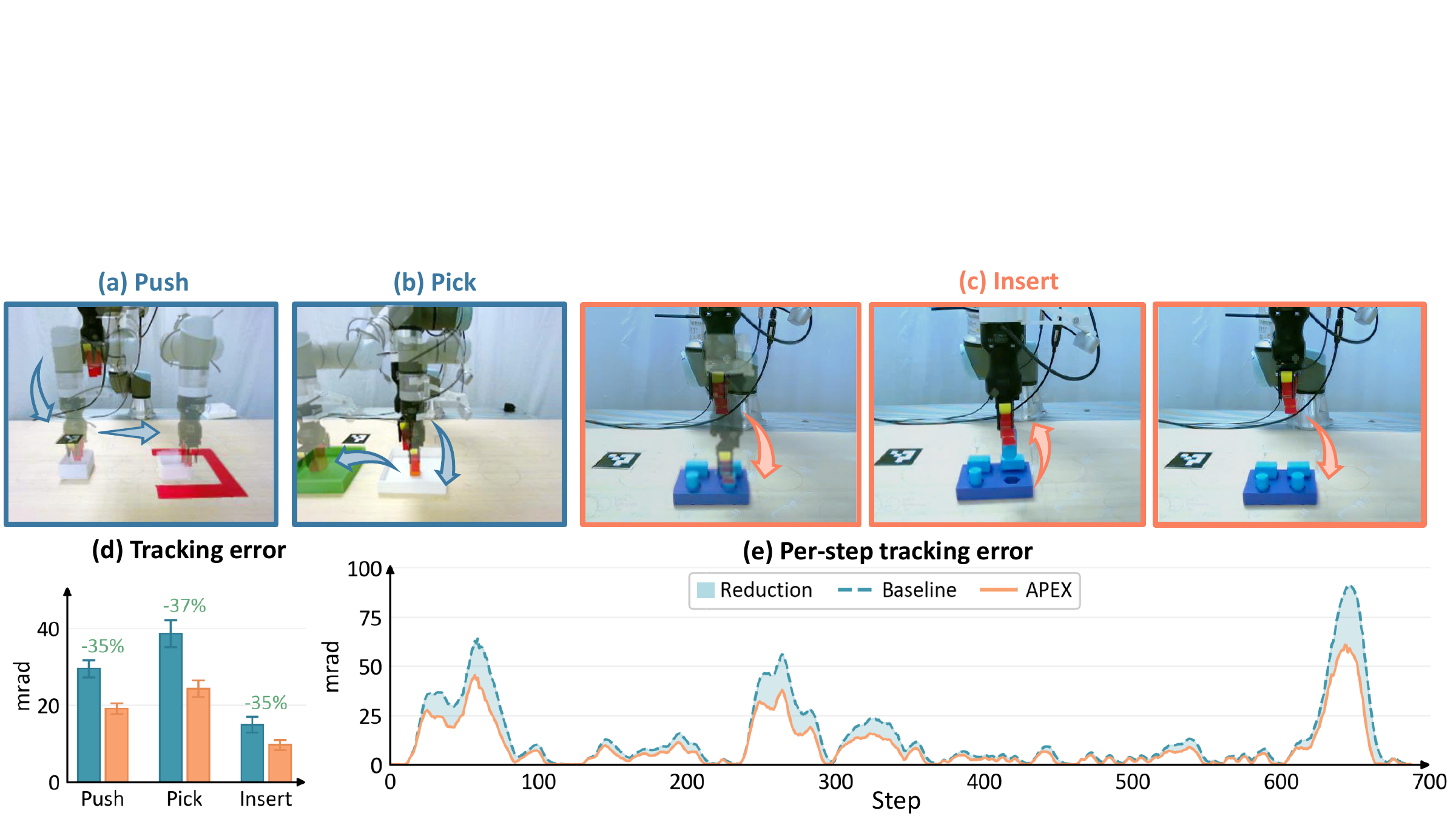
Real-Robot Deployment
On a physical UR5, APEX improves execution under the robot's native position servo. The largest gain appears on PegInsertion, where the flow matching policy improves from 20% to 35%. Rollouts are shown at 4x speed.
DP + APEX Rollouts
Raw DP vs DP + APEX
PushCube
PickCube
PegInsert
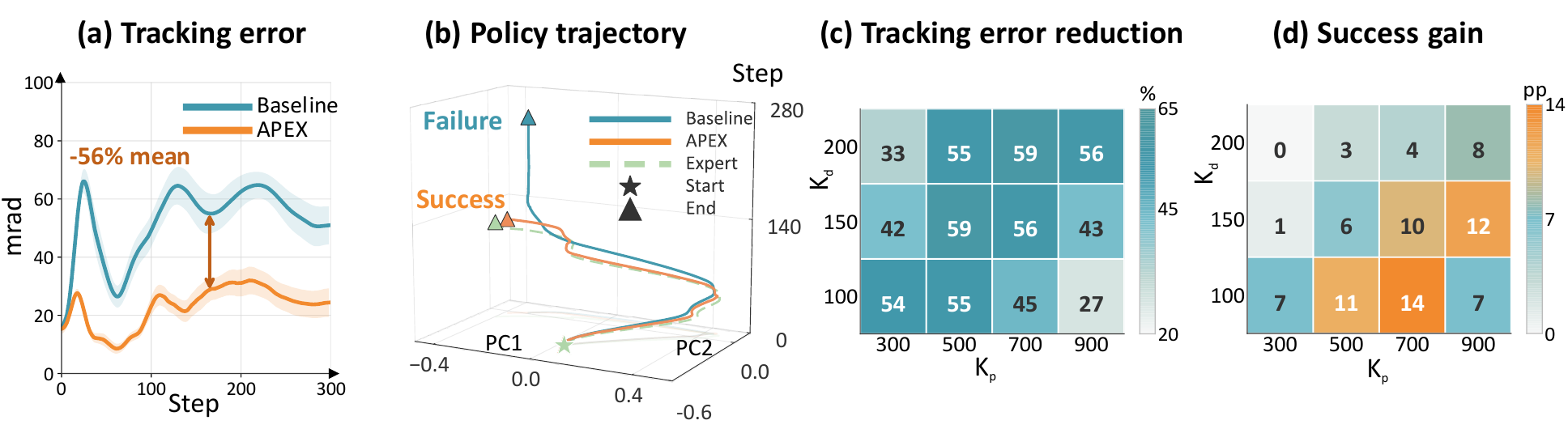
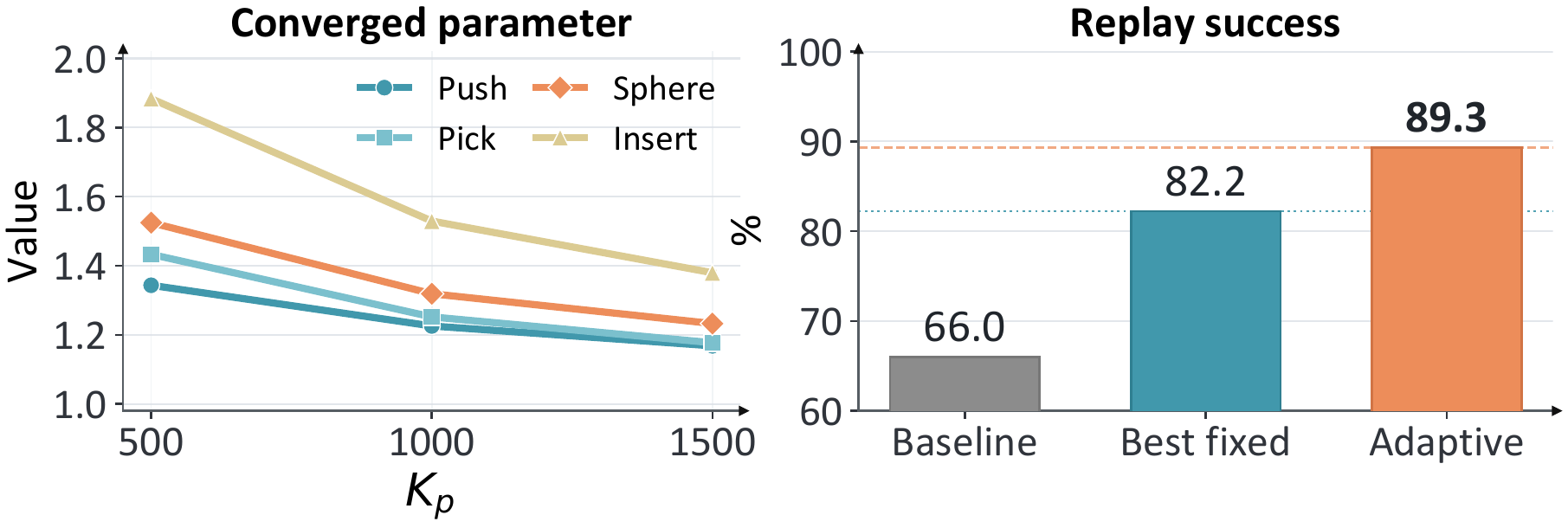
Adaptive Update
The adaptive update outperforms the best fixed correction and increases correction strength when tracking degrades.
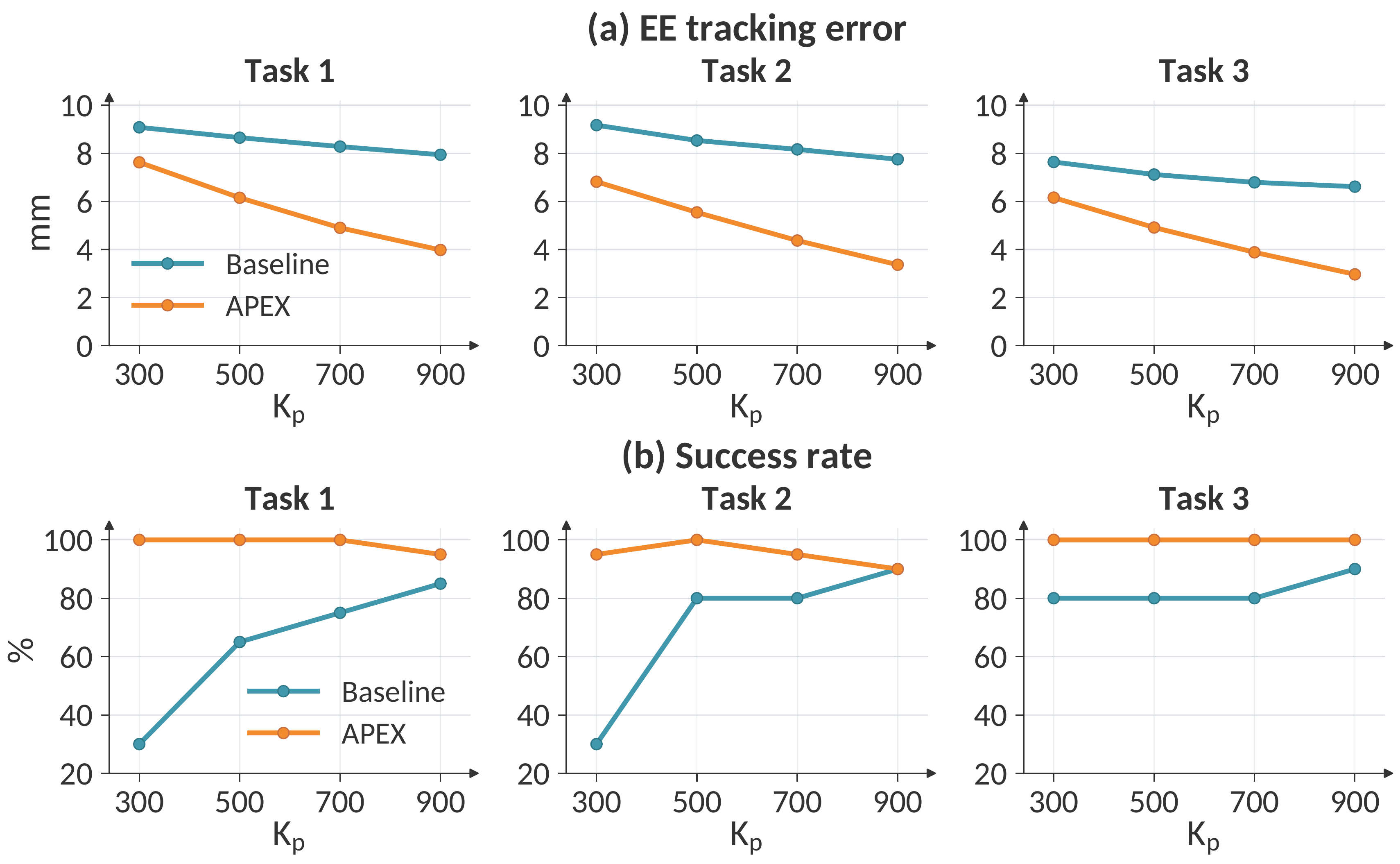
VLA Generalization
With π0.5 on LIBERO Spatial, APEX reduces end-effector tracking error and improves mean success from 72.1% to 97.9%.
BibTeX
@article{zhao2026apex,
title = {APEX: Adaptive Policy Execution for Precise Manipulation},
author = {Zhao, Mengfei and Jiang, Chenxi and An, Tuo and Jia, Jindou and Yang, Jianfei},
journal = {arXiv preprint},
year = {2026}
}